OpenClaw, Personal Assistants and the future of work
OpenClaw (https://openclaw.ai/) took the world by storm. It is the first working product that behaves more like a colleague than software — a personal assistant architecturally designed to handle real operational work. Not a chatbot. Not a wrapper around a language model.

OpenClaw took the world by storm. It is the first working product that behaves more like a colleague than software, a personal assistant architecturally designed to handle tedious operational work. Not a chatbot. Not a wrapper around a language model. It handles the tedious work that currently lives in someone's inbox, their calendar, their half-finished Notion docs, and their head.
OpenClaw might be the most powerful piece of software released after ChatGPT. It signals that the agentic layer is real and it's here today.
A truly useful personal agent
The right question isn't "what can AI do?" It actually is "what does a genuinely useful assistant do all day?" Those are very different questions, and most products are answering the wrong one.
Here's what we observed after integrating early versions of personal agents into actual workflows: the bottleneck is not intelligence. The bottleneck is context and continuity. A model can reason well. What it struggles with is remembering that you always push Tuesday standups when the CTO is traveling, or that a particular client needs three rounds of review before anything goes external.
That's the problem OpenClaw is built to solve. The architecture centers around three things:
- Persistent memory - not session-based, but longitudinal. The assistant builds a working model of how you operate.
- Judgment under ambiguity - knowing when to act, when to ask, and when to wait. This is the hard part. This is where most agent implementations fall apart.
- Action execution - The assistant needs to do things: send, schedule, draft, route, escalate.
The future of work this points toward isn't humans doing less. It's humans doing different things less coordination overhead, less context-switching, more actual thinking. The assistant absorbs the operational surface area so the person can go deeper on the work that actually requires them.
That's the bet. And it's one worth examining with care - because how you build the assistant shapes what kind of work it makes possible.
The Actual Signal Behind 250,000 Stars
250,000 GitHub stars in weeks. Not months. Weeks!!
That's not enthusiasm for a new tool - that's thirteen years of frustration finding an exit.
The stars aren't a vanity metric. They're a pressure reading. And the pressure had been building since 2011, when Siri shipped and everyone quietly agreed to pretend it was fine.
It wasn't fine. It still isn't. Siri can't reliably set two timers. Your calendar assistant books meetings over existing blocks. Your "intelligent" inbox still buries the email you actually needed. We normalized a category of software that consistently fails at the one thing it was supposed to do - understand what you meant and act on it correctly.
OpenClaw isn't impressive because it's technically novel. It's impressive because it's the first personal assistant that makes you feel like you're not constantly negotiating with a system that's pretending to understand you. The 250,000-star moment tells you something important about where we are: the bar wasn't set by what AI could do. It was set by what the incumbents chose to ship. Siri, Cortana, Google Assistant, these weren't resource-constrained moonshots. They were products built inside organizations where the assistant was never the primary business. It was a feature. A demo. A press release.
When something finally works the way it was always supposed to, people don't just adopt it. They flood toward it.
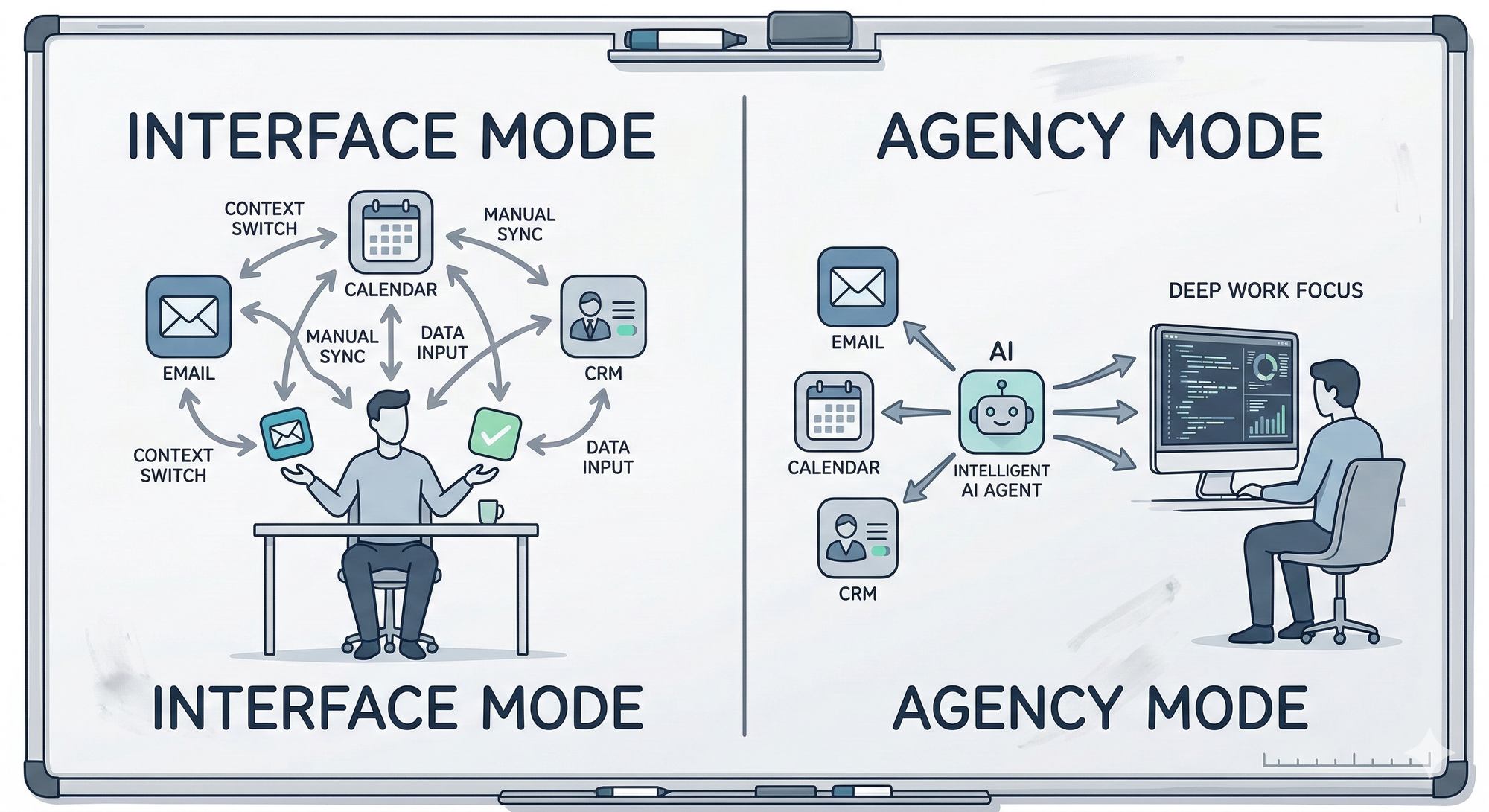
To understand why, you need to see the line that almost every previous "AI assistant" product has failed to cross - what I'd call the Interface vs. Agency divide. An interface helps you do work. An agent does work on your behalf. These are not the same thing. An interface requires you to remain in the loop for every decision, every action, every step. An agent takes a goal and runs with it.
Most products, including the ones that get breathless coverage, are still firmly in the interface category. They're faster, smarter interfaces, but interfaces nonetheless.
OpenClaw is the first mainstream open-source project that credibly crosses into the second category. That's the actual news.
Not the feature set. Not the benchmark scores. The category shift. And the 250k stars tell you that practitioners recognized it immediately - because they've been waiting for something that treats them as someone who needs work done, not just queries answered.
The Alternatives Landscape — Control vs. Convenience
That category shift raises an immediate question: if autonomous agents are the future, why would anyone choose anything else?
Because autonomy has a cost. And the question isn't which agent tool wins - it's what each tool's architecture reveals about the bet its builders made.
N8N, Sim.ai, and on-device LLMs aren't losing to OpenClaw-style autonomous agents. They're solving a different problem. And for large parts of the market, their problem is the more important one.
The Control Spectrum is a useful mental model here.
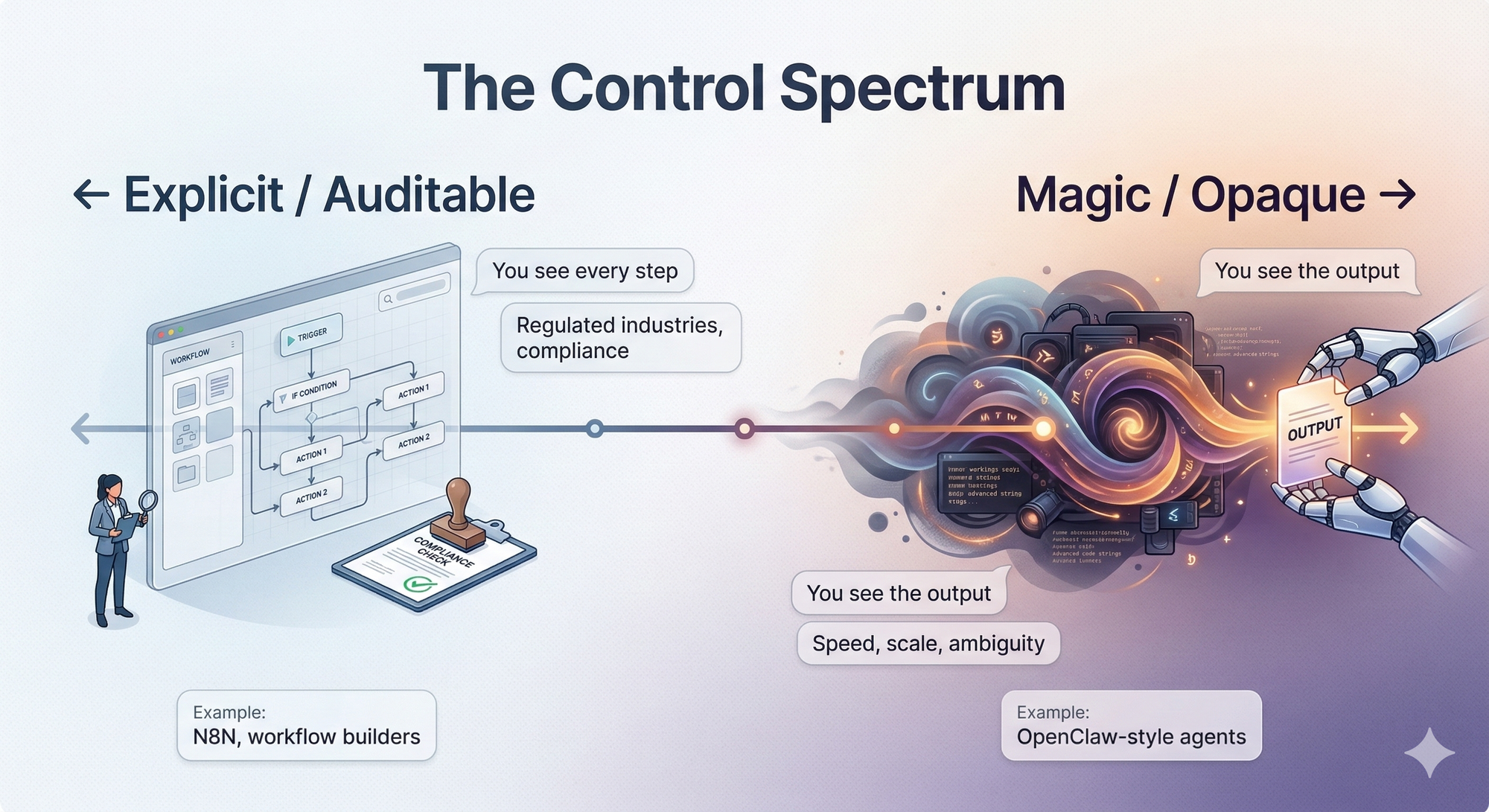
Most organizations need tools from both ends. The mistake is treating this as a binary. Here's what each alternative is actually betting on:
- N8N bets on auditability. The logic is visible, editable, inspectable. For anyone operating in a regulated environment - financial services, healthcare, legal - this isn't a feature preference. It's a compliance requirement. You cannot deploy an opaque agent that makes decisions you can't reconstruct. Full stop.
- Sim.ai bets on safety margins. Agent simulation before live deployment is the kind of thing that sounds optional until something goes wrong in production. Teams that need to test agent behavior against edge cases before those edge cases hit real customers - this is the tool for that.
- On-device LLMs bet on data sovereignty. Running inference locally means the data never leaves the machine. For a law firm, a hospital, or any organization handling sensitive information, this isn't paranoia. It's the minimum viable trust model.
The organizations that get this right aren't picking one end of the spectrum and committing. They're running explicit, auditable workflows for anything that touches compliance or customer data - and deploying autonomous agents where speed and ambiguity tolerance are high.
The architecture of a tool encodes a philosophy about who's in control and what they're willing to trade for it. N8N says: you stay in control, we make the logic visible. OpenClaw says: trust the agent, we'll handle the complexity. Neither is wrong. Both are right in the contexts they were built for.
The dangerous move is importing one philosophy into a context that demands the other.
Where Humans and Agents Actually Work Together
Choosing the right tool is necessary but insufficient. The harder question — and the one where most implementations quietly fail — is how humans and agents actually divide labor without the seams showing.
The future workplace isn't humans vs. agents. It's humans and agents working in parallel, with explicit handoff points, defined accountability, and trust boundaries that someone actually thought through in advance. The companies building that muscle memory now will have a structural advantage in 18 months that won't be easy to close.
Look at what Viktor is doing. The design philosophy is worth examining: an AI coworker built to slot into existing team workflows, not replace them. The bet isn't on autonomy - it's on augmentation with oversight. That's an important distinction, and most teams building internal agents are getting it backwards.
Here's what this looks like in practice. Take a business development team running a hybrid workflow: agents handle first-pass prospect research, CRM updates after calls, and meeting prep briefs. Humans own relationship judgment, negotiation posture, and final decisions on who to pursue. The handoff points aren't accidental - they're deliberate design choices made before the agent touched a single workflow.
That's the part most teams skip. And it's exactly where things break.
The same coordination problems that plague distributed teams - unclear ownership, communication gaps, trust deficits - show up in human-agent teams. The solutions rhyme.
I've seen this pattern repeatedly building distributed products. When ownership is ambiguous, things fall through. When communication channels aren't explicit, context gets lost. The problem isn't the technology. It's the coordination design.
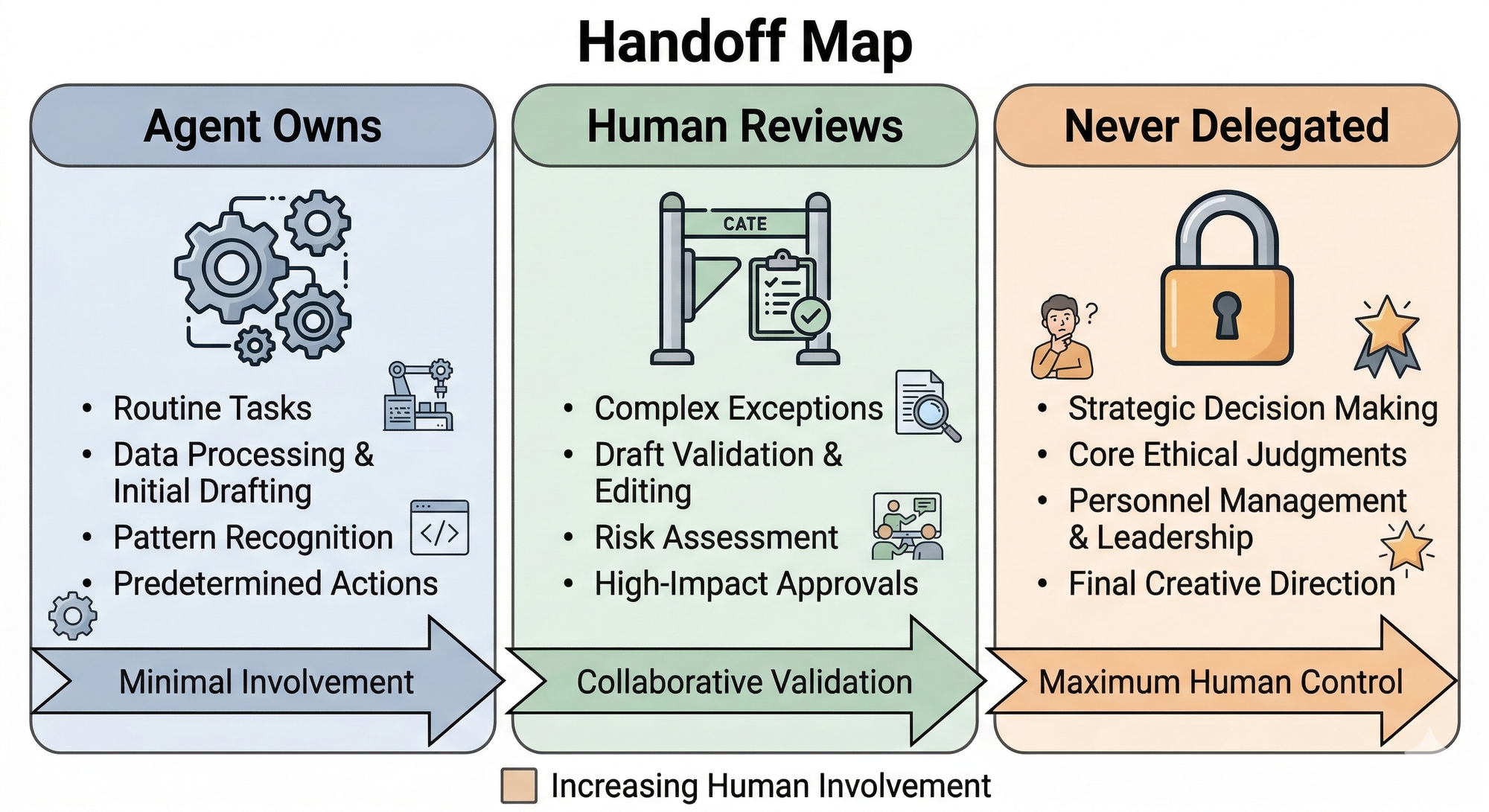
Which is why I'd push any team evaluating agent workflows to run what I call a Handoff Map before deploying anything. For every workflow you're considering, map three things:
- What the agent owns end-to-end - where it can act without a human in the loop
- Where the human reviews before the agent proceeds the checkpoints that exist because the cost of a mistake is too high to absorb silently
- What never gets delegated the decisions that stay human, full stop, regardless of how capable the agent becomes
Most teams do step one. Some do step two. Almost nobody does step three until something goes wrong. That third category - the non-delegables - is where you define what you actually trust, and what you're still accountable for. Skip it, and you'll find out later, in a way you won't enjoy.
The Limits You Need to Respect Before You Deploy Anything
The failure mode isn't that agents won't work. It's that they'll work just well enough to cause real damage before anyone notices.
Security and guardrails aren't things you bolt on after launch. They're architectural decisions - and if you're treating them as post-launch concerns, you're not being bold, you're being reckless.
If you're ready to implement your first Agent and Workflow reach out
Here's what the actual risk surface looks like:
- Prompt injection - Agents that browse the web or read external documents can be manipulated by malicious content embedded in those sources. This isn't theoretical. A supplier sends a contract with hidden instructions embedded in white text. Your agent reads it, follows those instructions, and does something you didn't authorize. That's a real attack vector, today.
- Data exfiltration - An agent with access to your calendar, email, and CRM is sitting on an enormous pile of sensitive business intelligence. The moment it calls an external API to book a flight, look up a contact, or check availability, you need to know exactly what data is leaving your environment and where it's going. Most teams don't.
- Hallucination in action - A chatbot that hallucinates is annoying. An agent that hallucinates and then acts, sends an email, updates a record, makes a booking is a liability! The output is no longer text on a screen. It's a change in the world.
- The audit trail problem If an agent takes an action and something goes wrong, can you reconstruct what happened and why? Most current tooling makes this harder than it should be. That's not acceptable when the agent is touching real workflows.
Before you deploy anything into a live workflow, assign it a trust tier:
- Read-only / advisory - The agent observes and recommends. No writes, no sends, no bookings.
- Draft and propose - The agent prepares an action; a human approves before it executes.
- Act with notification - The agent acts autonomously, but a human is immediately informed.
- Fully autonomous - The agent acts, and you find out in the logs.
Most organizations should start at Tier 1 or 2 and earn their way to higher tiers through demonstrated reliability — not assume their way there.
The trust tier isn't a permanent limitation. It's a calibration mechanism. You build the track record, then you extend the autonomy. That's not caution for caution's sake. That's how you avoid the kind of mistake that ends the whole experiment.
What to Actually Do
The question isn't whether to integrate agents into your workflows. That ship has sailed. The question is whether you do it with intention or by accident.
The organizations that get this right treat it like an architecture decision - something you reason through, document, and revisit. Not a tool purchase you justify after the fact. Here's the sequence that you can use:
- Pick one workflow and map it completely. Not "let's add AI to everything" - that's how you get a sprawling mess you can't audit or fix. Start with one high-frequency, lower-stakes workflow: meeting notes, research summaries, first-draft responses. Write down every step before you hand any of it to an agent. If you can't map the workflow on a whiteboard, you're not ready to automate it.
- Decide your control model before you touch tooling. OpenClaw-style autonomy or N8N-style explicit workflows? That answer should come from the workflow's risk profile, not your enthusiasm for the technology. High-stakes, customer-facing, irreversible actions - go explicit. Low-stakes, internal, easily corrected - you can give the agent more rope.
- Build the audit trail before you need it. Log agent actions from day one. Every decision, every tool call, every output. You'll think it's overkill until the first time something goes wrong and you're trying to reconstruct what happened. That moment will come.
- Set the trust tier explicitly and make it a team decision. Use the framework from the previous section. Write it down. "This agent can read and summarize. It cannot send, post, or modify." Individual enthusiasm is how you end up with an agent that emailed a customer something it shouldn't have.
- Run a red team exercise before any agent touches real data. Have someone spend an afternoon trying to break it - prompt injection, edge cases, adversarial inputs. This is not a nice-to-have. It's a one-afternoon investment that sits between you and a catastrophic incident.
The organizations that will get hurt aren't the ones moving slowly. They're the ones moving fast without a model for what could go wrong.
None of this is complicated. It's just the discipline of treating agent integration as engineering, not experimentation.
The Actual Decision
The organizations that will look back on this period as a competitive inflection point are the ones that treated agent integration as a design problem, not a procurement problem.
That distinction matters more than it sounds. Procurement thinking asks: which tool do we buy, which vendor do we sign, which demo impressed the committee? Design thinking asks: what are we actually trying to do, where does human judgment remain irreplaceable, and how do we build the connective tissue between the two? One of those questions leads to a shelf of unused subscriptions. The other leads to workflows that compound.
OpenClaw's 250k stars don't tell you what you need to build. They tell you the demand is damn real that ignoring it is now a deliberate choice, not a default. Viktor and N8N tell you the patterns are emerging - that personal AI assistants wired into operational infrastructure aren't science fiction, they're a weekend project away from production for teams that know what they're doing. The limits like context windows, hallucination under ambiguity, the brittleness of long agent chains tell you where the bodies are buried. Where the teams that moved fast and didn't think hard enough are now rebuilding.
The question isn't if agents belong in your organization's future. It's whether you're approaching that future with the same rigor you'd apply to any other system design decision, or whether you're letting the hype make the architectural choices for you.
The gap between the teams who've internalized that and the ones still running pilots without a thesis is already visible. In twelve months, it'll be a canyon.
What you do with that is the actual decision.
Frequently Asked Questions
"What is OpenClaw and how is it different from existing AI assistants?"
OpenClaw is an open-source personal assistant architecture built around persistent memory, action execution, and judgment under ambiguity designed to do work on your behalf, not just respond to queries. The distinction is the Interface vs. Agency divide: most AI assistants, including Siri and Google Assistant, are faster interfaces that keep you in the loop for every decision. OpenClaw is built to cross into true agency like take a goal, hold context across time, and act. That's the category shift that explains 250,000 GitHub stars in weeks.
"Why does the Interface vs. Agency distinction actually matter for teams evaluating AI tools?"
An interface requires you to remain in the loop for every action; an agent takes a goal and runs with it - and that difference has direct consequences for how much operational overhead you actually shed. If your team is still manually reviewing every step the AI takes, you haven't reduced coordination cost, you've just added a new coordination layer. The compounding value of agent-style architectures only materializes when you've designed deliberate handoff points and trust tiers - otherwise you get the liability without the leverage.
"How does persistent memory change what a personal assistant can actually do?"
Persistent, longitudinal memory is what separates a capable assistant from a capable session, it's the difference between a tool that can reason and one that actually knows how you work. A model without memory can answer questions well; a model with longitudinal context knows that you always push Tuesday standups when the CTO is traveling, or that a specific client requires three rounds of review before anything goes external. That operational knowledge is currently living in someone's head, and it's the bottleneck that raw model intelligence alone can't fix.
"How do I structure a human-agent workflow without the handoffs breaking down?"
Run a Handoff Map before any agent touches a live workflow: define what the agent owns end-to-end, where a human reviews before the agent proceeds, and what never gets delegated regardless of capability. Most teams do the first step and skip the third, the non-delegables, and that's exactly where things break in ways you find out about later. Write it down, make it a team decision, and treat it as a design artifact, not a verbal agreement.
"When should I choose N8N-style explicit workflows over an autonomous agent like OpenClaw?"
The answer should come from the workflow's risk profile, not your enthusiasm for the technology. If the workflow touches regulated data, customer-facing decisions, or irreversible actions, go explicit and auditable - N8N's visible, inspectable logic isn't a feature preference in those contexts, it's a compliance requirement. Autonomous agents earn their place in workflows where speed matters, ambiguity tolerance is high, and mistakes are recoverable. Most organizations need both ends of that spectrum and make the mistake of treating it as a binary.
"Isn't deploying an AI agent just a matter of picking the right tool and turning it on?"
Agent deployment done that way is how you get a system that works just well enough to cause real damage before anyone notices. Security guardrails, trust tiers, and audit trails aren't post-launch concerns, they're architectural decisions that have to be made before the agent touches a live workflow. The teams that treat this as a procurement decision rather than a design problem are the ones quietly rebuilding three months later.
"What are the real security risks of running autonomous agents in production workflows?"
The four risks that actually matter in production are prompt injection, data exfiltration, hallucination-driven action, and a missing audit trail. A hallucinating chatbot is annoying; a hallucinating agent that then sends an email or updates a CRM record is a liability, the output is no longer text on a screen, it's a change in the world. Assign every agent a trust tier before deployment, log every action from day one, and run a red team exercise before any agent touches real data. That's a one-afternoon investment that sits between you and a catastrophic incident..
"Does moving to AI agents mean humans do less work??"
The future of work that autonomous agents point toward isn't humans doing less, it's humans doing different work. The assistant absorbs operational surface area: coordination overhead, context-switching, first-pass research, scheduling logic. That's supposed to free the person to go deeper on the work that actually requires human judgment, relationship intelligence, and accountability. Whether that shift actually happens depends entirely on whether the handoff design is intentional, the technology makes it possible, the coordination design makes it real.
If you're ready to implement your first Agent and Workflow reach out



